NAACL 2019 tutorial on “Transfer Learning in Natural Language Processing” 的部分笔记,资料链接见文末。
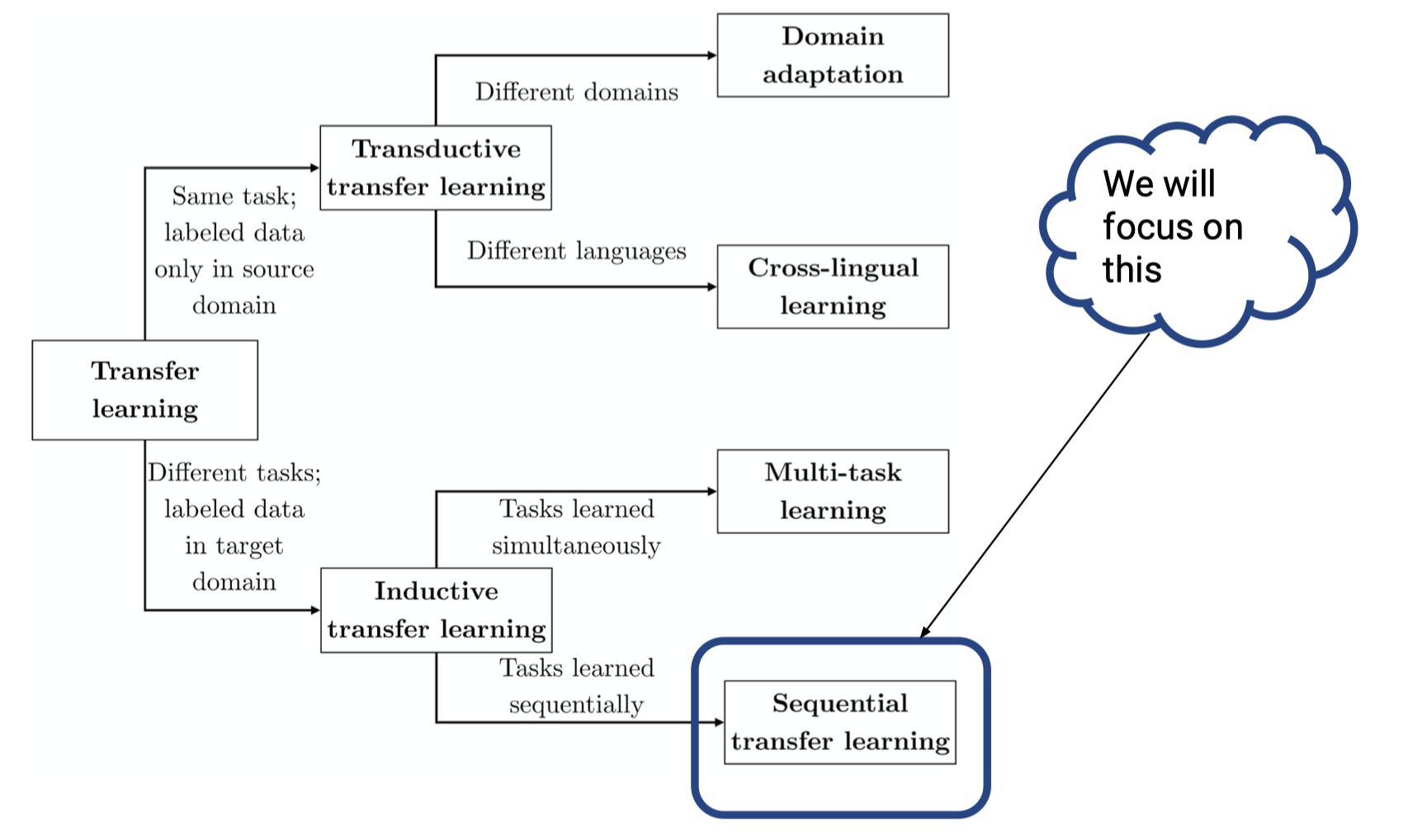
迁移学习的概念就不多描述了,可以参考迁移学习小册子,讲的非常好。总的来说迁移学习有两大类(应该是 Sebastian Ruder 博士论文提出的分类?):
- Inductive transfer learning
- 任务不同,但在目标领域有标注数据
- 同时学习不同任务就是 multi-task learning,顺序学习不同任务就是 sequential transfer learning
- 具体方法有基于样本(instance based transfer)、基于特征(feature representation transfer)、基于参数(parameter transfer)、基于关系(relational knowledge transfer)的迁移,其中最为常见的就是基于特征的迁移,如把预训练模型当做特征提取器,后加分类层等应用,以及基于参数的迁移,如我们常用的 fine-tuning
- Transductive transfer learning
- 任务相同但是领域不同,源领域有标注数据,但是目标领域没有标注数据
- 不同领域就是领域适应(domain adaptation),不同语言就是跨语言学习(cross-lingual learning)。领域适应问题一般假设源领域和目标领域有相同的样本空间,但数据分布不一致,迁移学习小册子重点介绍了这一热门研究方向
- 通常是基于样本和基于特征的学习
这一篇关注的是 Sequential inductive transfer learning,通常来说第一阶段在源领域上预训练,学习 general 的一些表征,然后做 adaption,迁移到新的任务。由于源领域的训练数据非常大,预训练模型通常有很好的泛化能力(参考大力出奇迹的 GPT3)。预训练之前讨论的比较多,而这次要解决的问题是 How to adapt the pretrained model in NLP,主要从下面三个方面进行讨论:
- Architectural modifications?
怎么改模型结构 - Optimization schemes
去训练哪些权重,以什么顺序来训练 - More signal: Weak supervision, Multi-tasking & Ensembling
获取更多监督信号
Architecture
有两种选择,大多数情况下第一种选择就可以解决问题:
- 模型内部结构不变,可以在最上层加分类器,在最下层补充 embdding,也可以把模型输出当做特征
- 一方面,删除一些对目标任务无效的 pretraining task head,像是预训练 LM 的 softmax 分类器,当然也可以留着做 multi-task
- 另一方面,在顶层或者底层加上目标任务需要的层,简单来讲可以加个 linear 层,复杂一点也可以把模型输出当做目标模型的输入
- 修改模型内部结构,如改成 encoder-decoder 模式,或者为目标任务加一些 adapters(像加在 transformer 上的 multi-head attention,layer norm)等
- BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning
- Parameter-Efficient Transfer Learning for NLP
- Adaptation layer 在 CV 领域有更广泛的研究,这里提到的 adapters 是为了优化目标任务,而 CV 领域提到的自适应模块是为了 domain adaption 提出的,通常用来完成 source 和 target 数据的自适应,拉近两者的数据分布,使得网络效果更好,常见的有在分类器的前一层/几层加入适配层(如 MK-MMD),用来计算 source 和 target 的距离,加入损失进行训练
Optimization
几个需要考虑的问题:
- 选择更新哪些权重(Which weights)
- 不更新权重:feature extraction
- 更新权重:fine-tuning
- Adapters
- feature extraction 还是 fine-tuning 取决于目标任务和预训练任务之间的相似性
- 选择什么时候更新,以及怎样更新(What schedule)
- top-bottom
- gradual unfreezing
- discriminative fine-tuning
- 考虑一些 trade-offs
时间/空间复杂度,性能要求
Which weights
Freeze pretrained weights
来看图说话:
- 不更新预训练的权重,只训练目标任务相关的权重(比如新加的分类层)
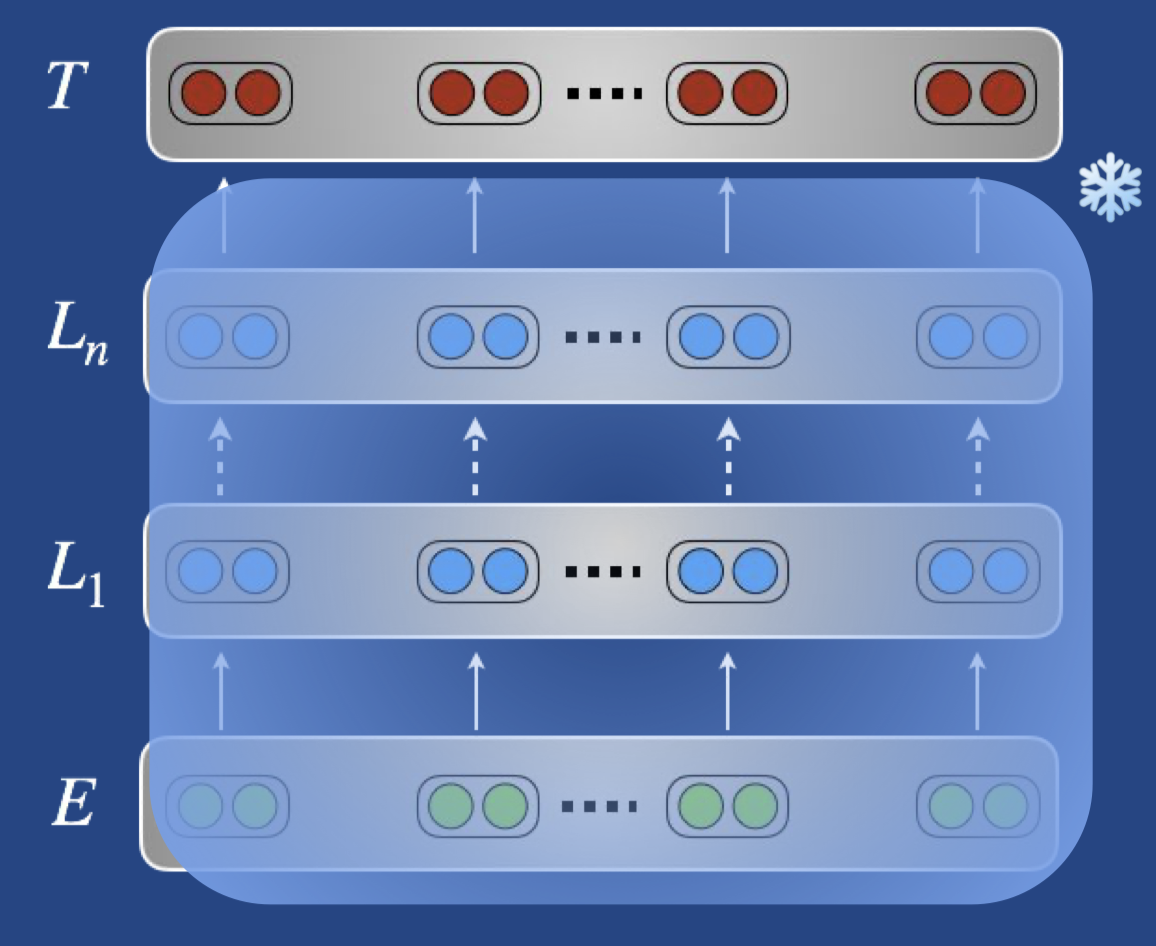
- 特征提取要注意的是不要傻傻的只用 top layer 的特征,可以学习各层特征的线性组合
Deep contextualized word representations 2018
Latent Multi-task Architecture Learning 2019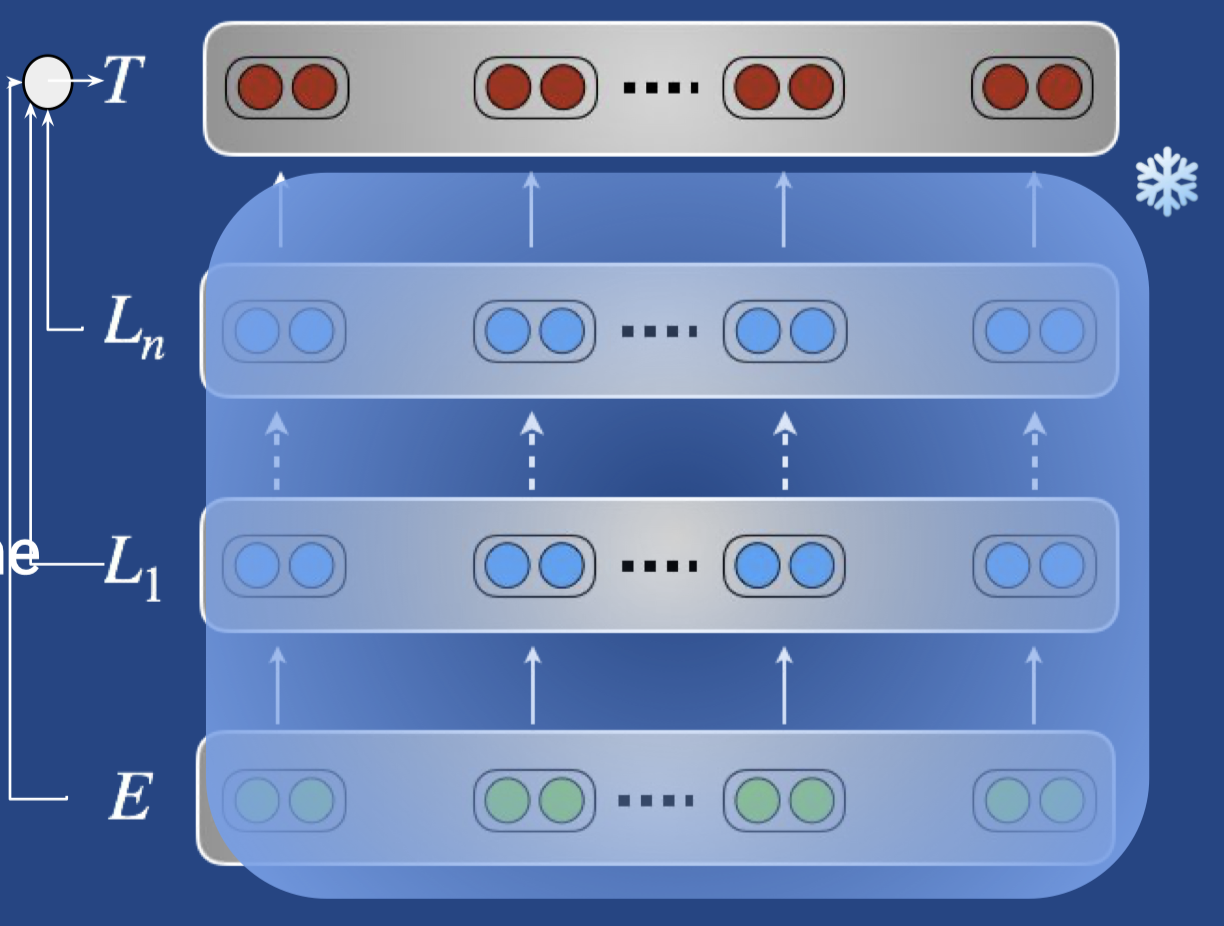
- 预训练特征当做下游任务的特征
- Adapters,在预训练模型结构已有的 layers 之间加入目标任务的适配器,如下图,只训练红色部分的权重
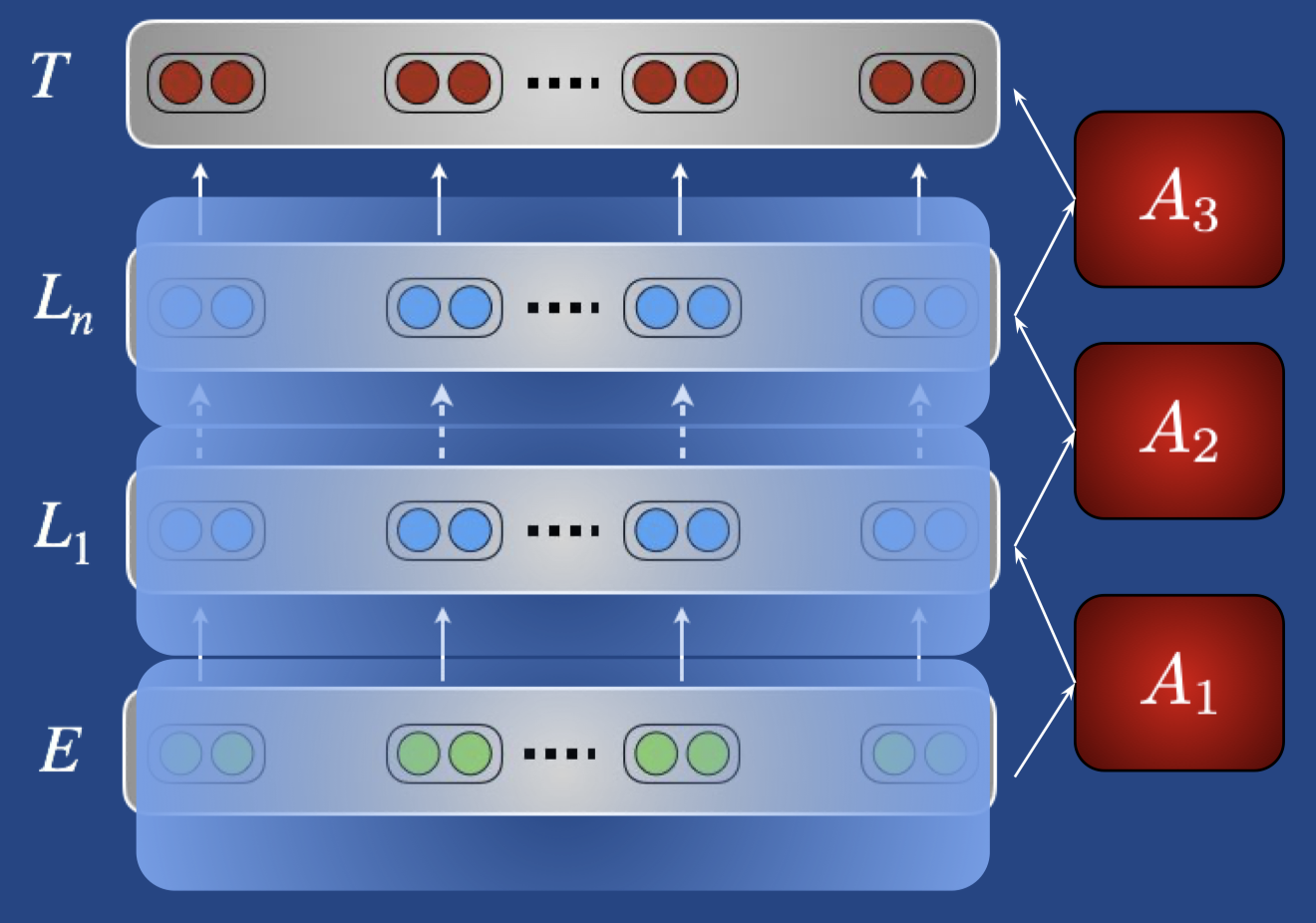
Change pretrained weights
另外一种就是 fine-tuning 啦,用预训练的权重来初始化下游模型的参数,在迁移阶段训练所有参数
What schedule
决定好更新什么权重,下一步就要看用什么顺序,以及怎样的方式来更新了,记住我们的目标:
We want to avoid overwriting useful pretrained information and maximize positive transfer.
在一个完全不同的领域/任务上直接对所有层进行更新可能会带来不稳定的结果,所以更明智的选择是分层训练,给不同的 layer 一点时间来适应新的任务和数据,这感觉就像是回到了 DL 初期的 layer-wise 训练方法(Hinton et al., 2006,Bengio et al., 2007)。
Anyway,一个重要的指导原则是自顶向下(top-to-bottom)的更新,也就是先 freeze 住低层的参数,去更新高层的参数,因为高层的参数更加的 task-specific。这里要考虑的是 time 和 intensity,每一层更新的时间可以通过 freeze 其他层来控制,更新的强度可以通过学习率的变化来控制。另外,可以通过正则化来平衡更新与保留之间的关系。
Time
自底向上,从 embedding 到中间层到 top layer 再到 target layer 各层表示为:E -> L1 -> … Ln -> T。
- Freezing all but the top layer 只训练 top layer Ln
Long et al.,ICML 2015 - Chain-thaw
Felbo et al., EMNLP 2017- 只训练 T 层参数
- 自底向上,每次只训练一层的参数,E -> L1 -> … -> Ln
- 训练所有层
- Gradually unfreezing
Howard & Ruder, ACL 2018
逐层解冻,先训练 T,训练 T + Ln,训练 T + Ln + Ln-1,直到全部放开训练所有层 - Sequential unfreezing
Chronopoulou et al., NAACL 2019
用超参来决定 fine-tuning 的过程- 先训练新增参数,训练 n epochs
- 训练除 embedding 层外的所有层,训练 k epochs
- 训练所有层直到收敛
这里多数的方法到最后都会一起训练所有的参数
Intensity
降低学习率来防止重写有用信息,问题是什么时候降低学习率?
- Lower layers,捕捉底层信息的时候
- Early in training,模型还需要去适应目标分布
- Late in training,模型快收敛的时候
如 ULMFiT 一文提到了一些技巧,一个是 discriminative fine-tuning,每层设置一个学习率,越底层学习率越小,另一个是 slanted triangular learning rates,学习率先逐渐增加后逐渐下降,相当于 warm up。
Regularization
用来减小灾难性遗忘,通过一个正则项来让目标模型参数接近预训练参数,让模型不要忘记预训练时学到的东西。
- 最简单的方法 Wiese et al., CoNLL 2017
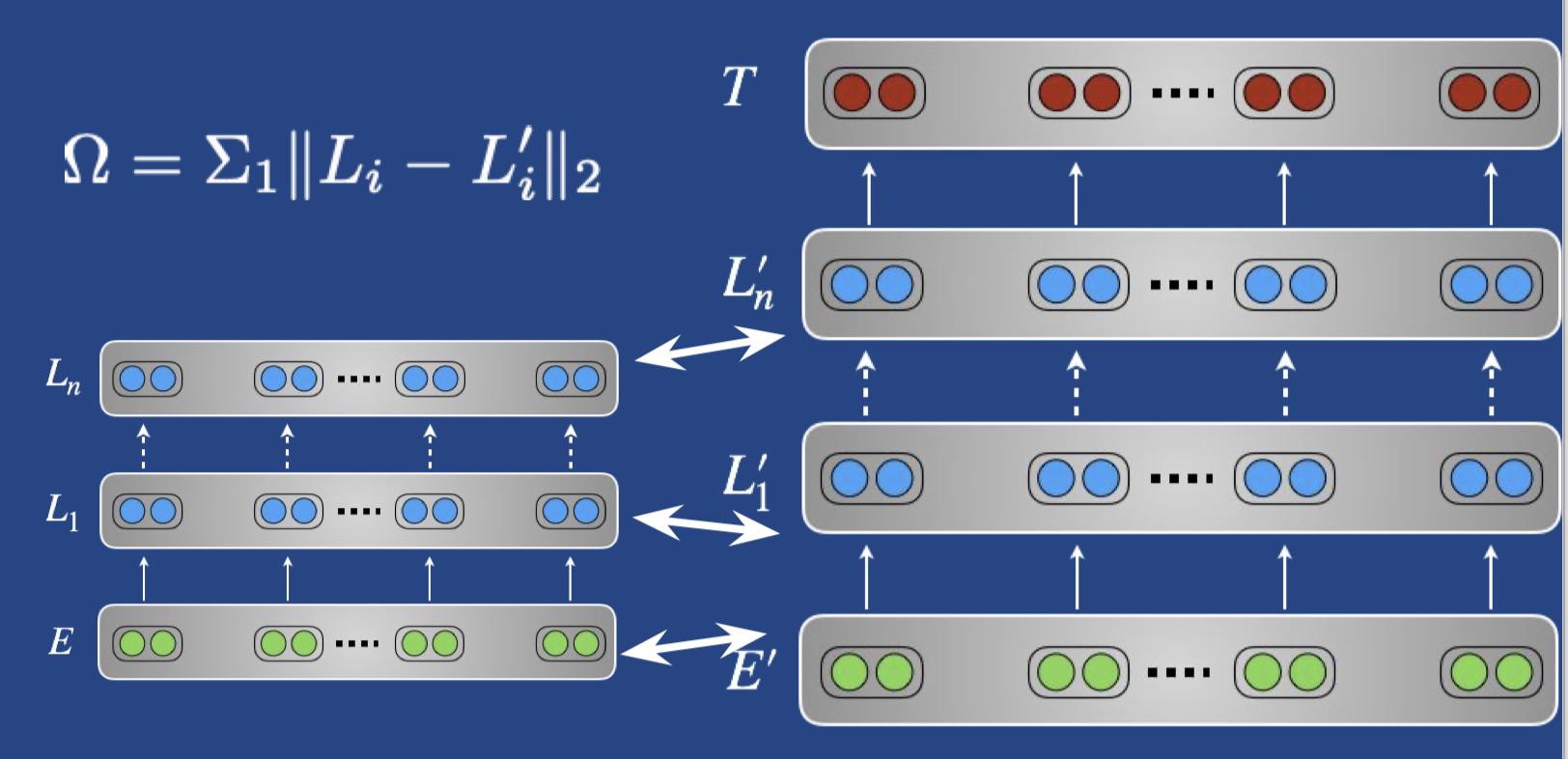
- 高级一点的方法(elastic weight consolidation; EWC)Overcoming catastrophic forgetting in neural networks
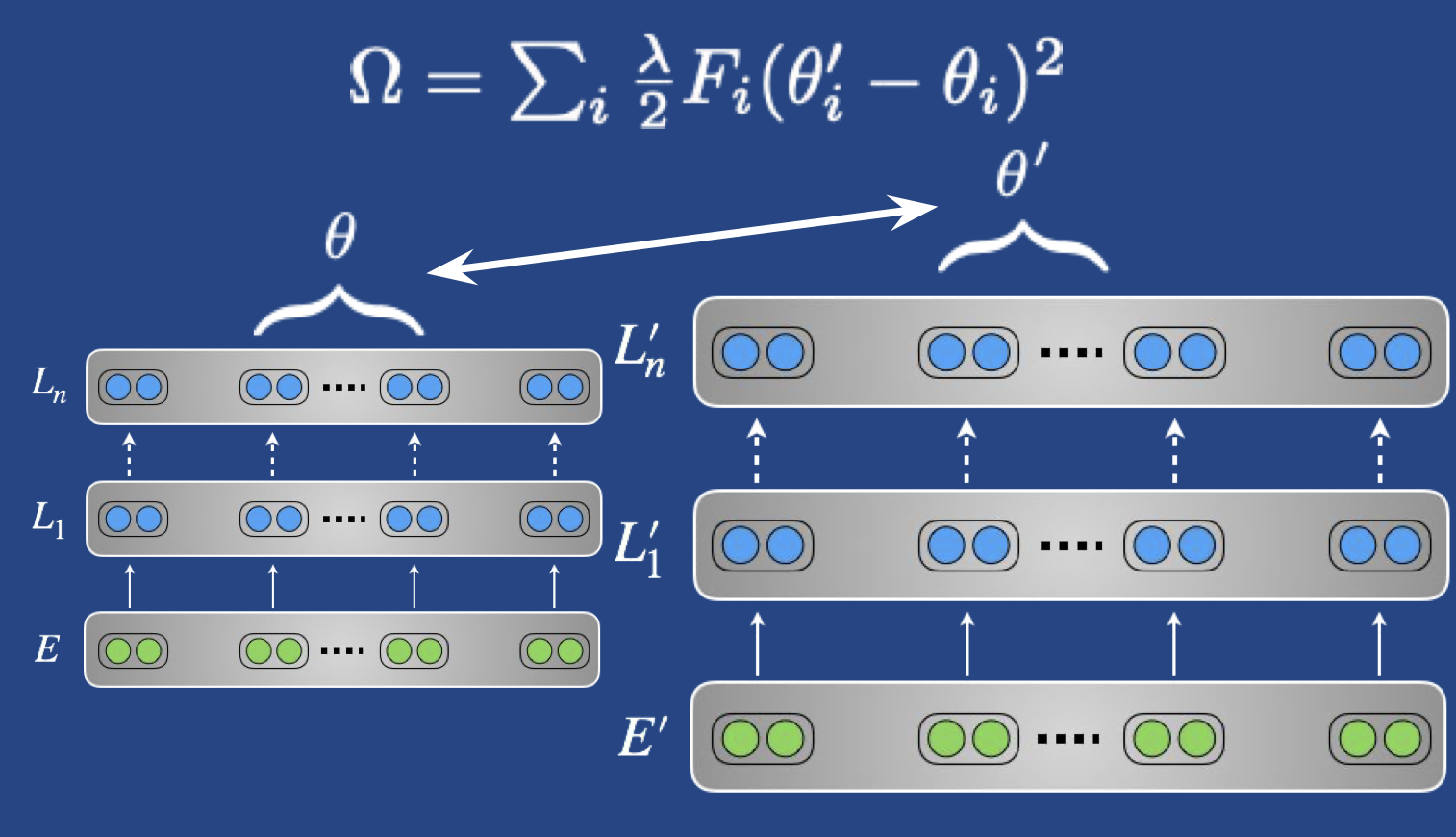
- 如果任务之间很相似,可以用交叉熵来鼓励 source 和 target 的预测相近,类似蒸馏的做法
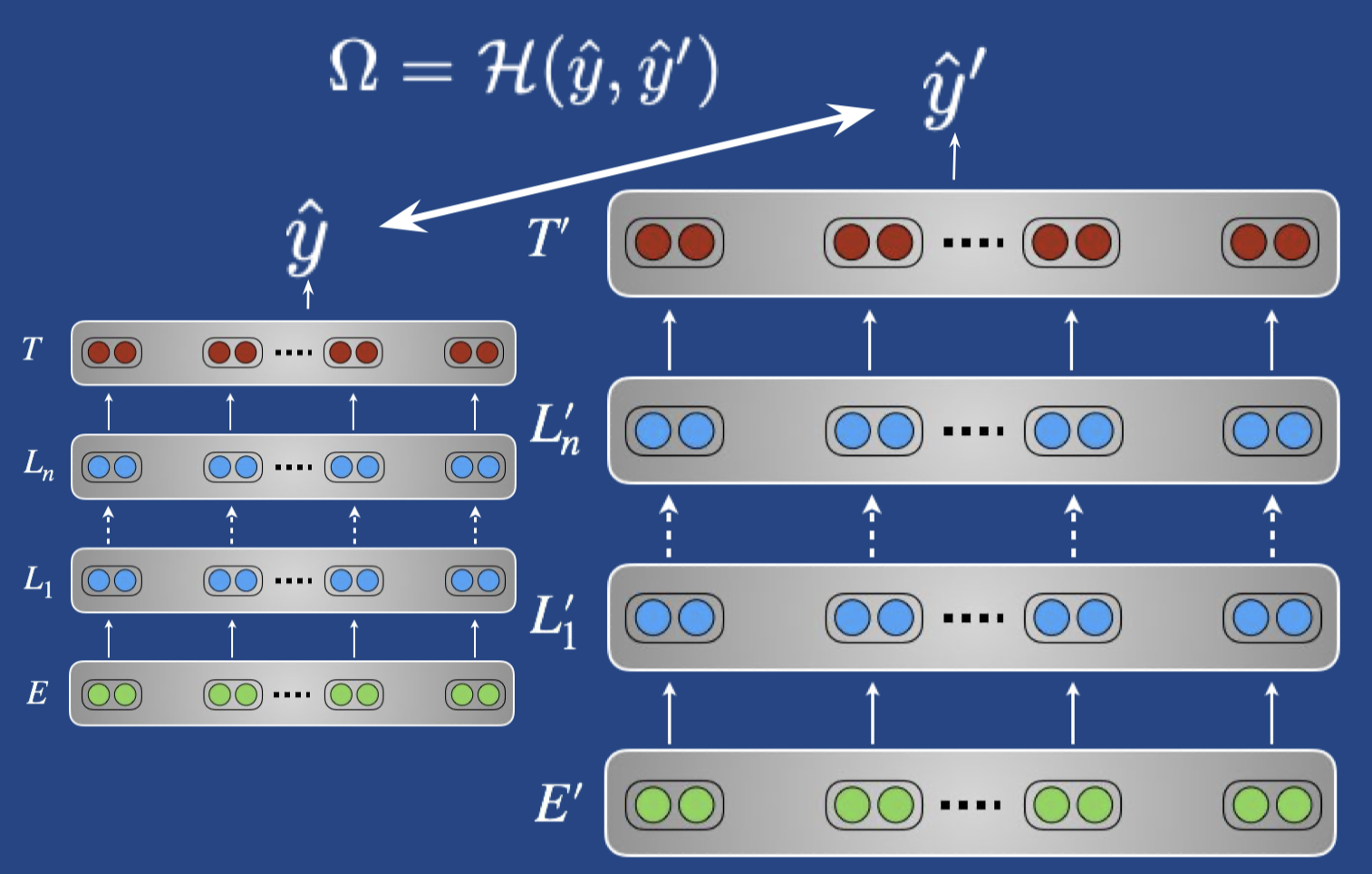
Trade-offs
选择权重更新时,不可避免的要考虑空间、时间复杂度、性能等问题。在时间、空间复杂度的要求上,都是 feature extraction > adapters > fine-tuning。
考虑 performance 的话,有一条经验法则:
If task source and target tasks are dissimilar, use feature extraction – To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks
事实上,大部分情况下 feature extraction 和 fine-tuning 的效果都差不多,除非任务非常相似,那么 fine-tune 强,或者非常不相似,那么 feature extraction 更胜一筹。一个例子是,在文本相似度任务上,BERT 上进行 fine-tune 的效果比 feature extraction 显著要好很多,这大概是因为 BERT 的 NSP 任务和 STS 任务非常相似;同样的,skip-thoughts 和 quick-thoughts 同样也用了 NSP 任务,在 STS 这类相似度任务上表现的也很好;而相反,ELMo 这种纯 LM 预训练目标的模型在 sentence pair tasks 上 fine-tune 的表现就不如人意了。另外,对于文本相似度这类 sentence pair 的任务,通过实验也可以发现,它依赖的并不是顶层的预训练特征(如下图,用 4-5 层之后的特征效果提升就显得非常平缓了),这也解释了为什么 fine-tune 的方法会更好一些。
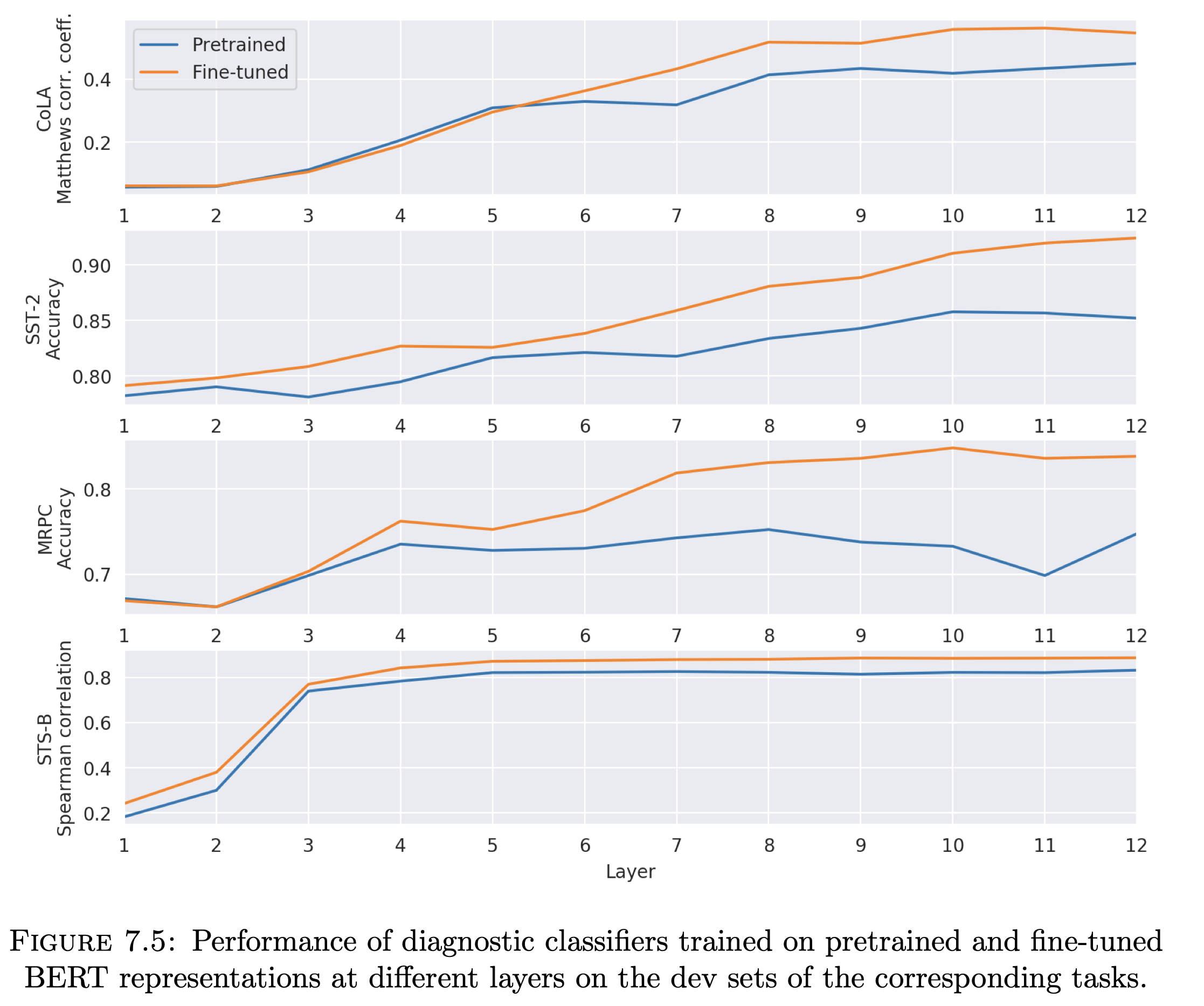
另外,Adapters 的效果和 fine-tuning 有的一拼,Transformers 结构相比于 LSTMs 要更容易 fine-tune,对超参更不敏感。
More signal
目标任务的数据量/标签一般都比较少,所以我们通常会通过组合一些信号来提高效果,从最基础的在单目标任务上 fine-tune 单模型,可以延伸到从其他数据集/相关任务中收集信号(Weak Supervision, Multi-tasking and Sequential Adaptation),再到集成模型,结合多个 fine-tune 模型的预测。
Basic fine-tuning
以一个分类任务为例,简单来说就是下面几步:
- 从模型提取一个 fixed-length vector,可以是 CLS 的 hidden state,也可以是所有 hidden-states 的平均/最大池化
- 额外的分类层投射到分类空间
- 训练分类目标
Related datasets/tasks
从其他数据集和相关任务中收集更多监督信号。
- Sequential adaptation
- 在相关数据集/任务上先做一次微调
- 适用于数据有限但有一些相似任务的情景,先在有更多数据的相关任务上进行 fine-tune,然后再在目标任务上 fine-tune
- 也可以在没有标注数据的领域数据上用 LM 等任务进行 fine-tune,然后在目标任务上 fine-tune
- 2018 Sentence Encoders on STILTs: Supplementary Training on Intermediate Labeled-data Tasks
- 2019 Learning and Evaluating General Linguistic Intelligence 在目标任务上提高样本的复杂度
- Multi-task fine-tuning with related tasks
- 如 NLI tasks in GLUE
- 每个 step 采样一个任务和一个 batch 来训练,多任务训练的方式训练几个 epochs,最后在目标任务上 fine-tune 几个 epochs
- LM 很有用
- 即使没有预训练也有用 Semi-supervised Multitask Learning for Sequence Labeling
- 引入 lambda 比率 An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models $L = L1 + \lambda L2$
- 这在 ULMFiT 里作为一个单独的步骤
- Dataset Slicing
- when the model consistently underperforms on particular slices of the data
- 用 error analysis 挑选子集
- 用经验自动选择一些挑战性的数据子集
- auxiliary head 和 main head 一起训练
- 只在特定的数据子集上训练额外的 head
- Massive Multi-Task Learning with Snorkel MeTaL
- when the model consistently underperforms on particular slices of the data
- Semi-supervised learning
- 可以使模型预测结果和未标注的数据更加一致
- 基本思路是最小化在原始输入 x 上的预测与引入扰动后的输入 x’ 的预测之间的距离

- 扰动可以是
- noise, masking
- data augmentation, e.g. back-translation
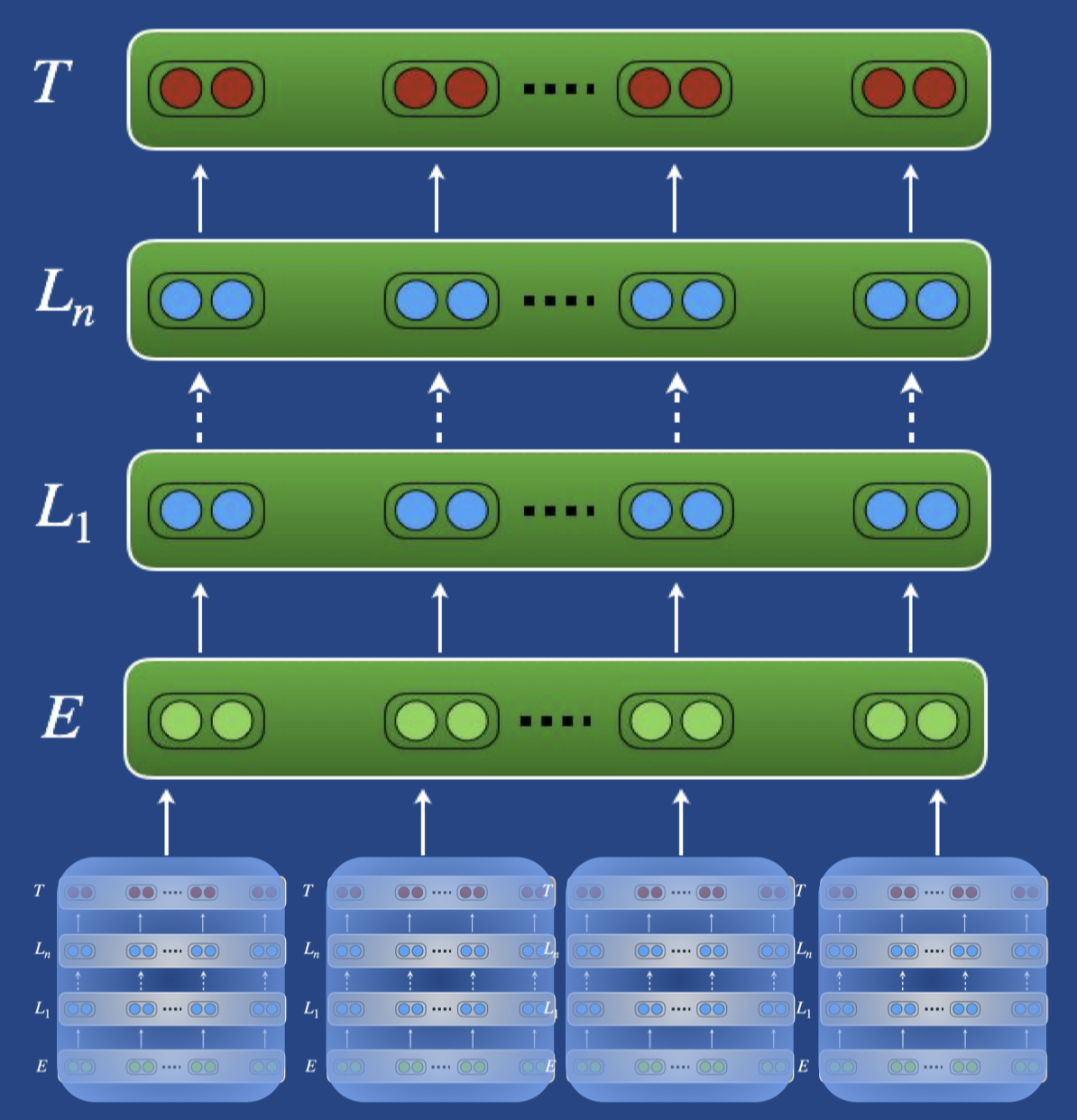
Ensembling
- Ensembling models
- on different tasks
- on different dataset-splits
- with different parameters (dropout, initializations…)
- from variant of pre-trained models (e.g. cased/uncased)
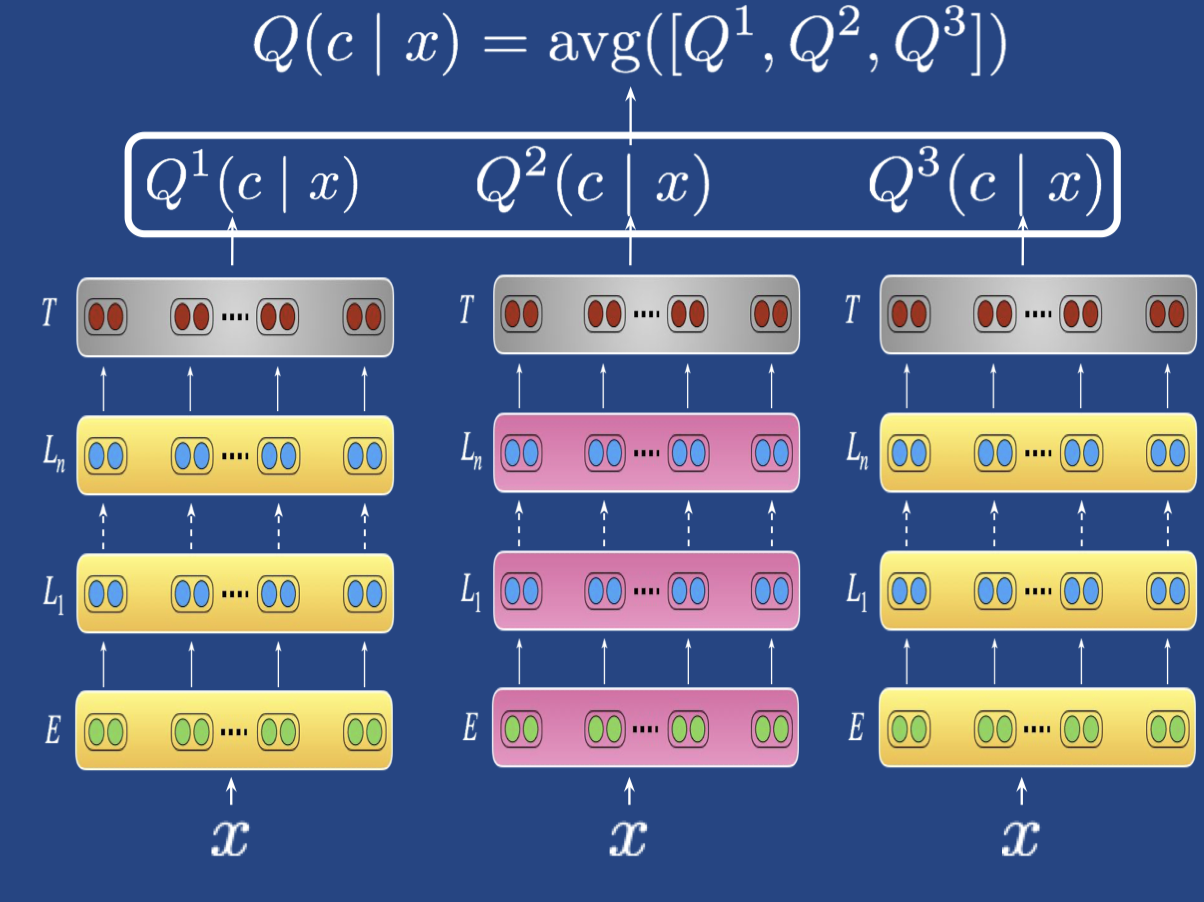
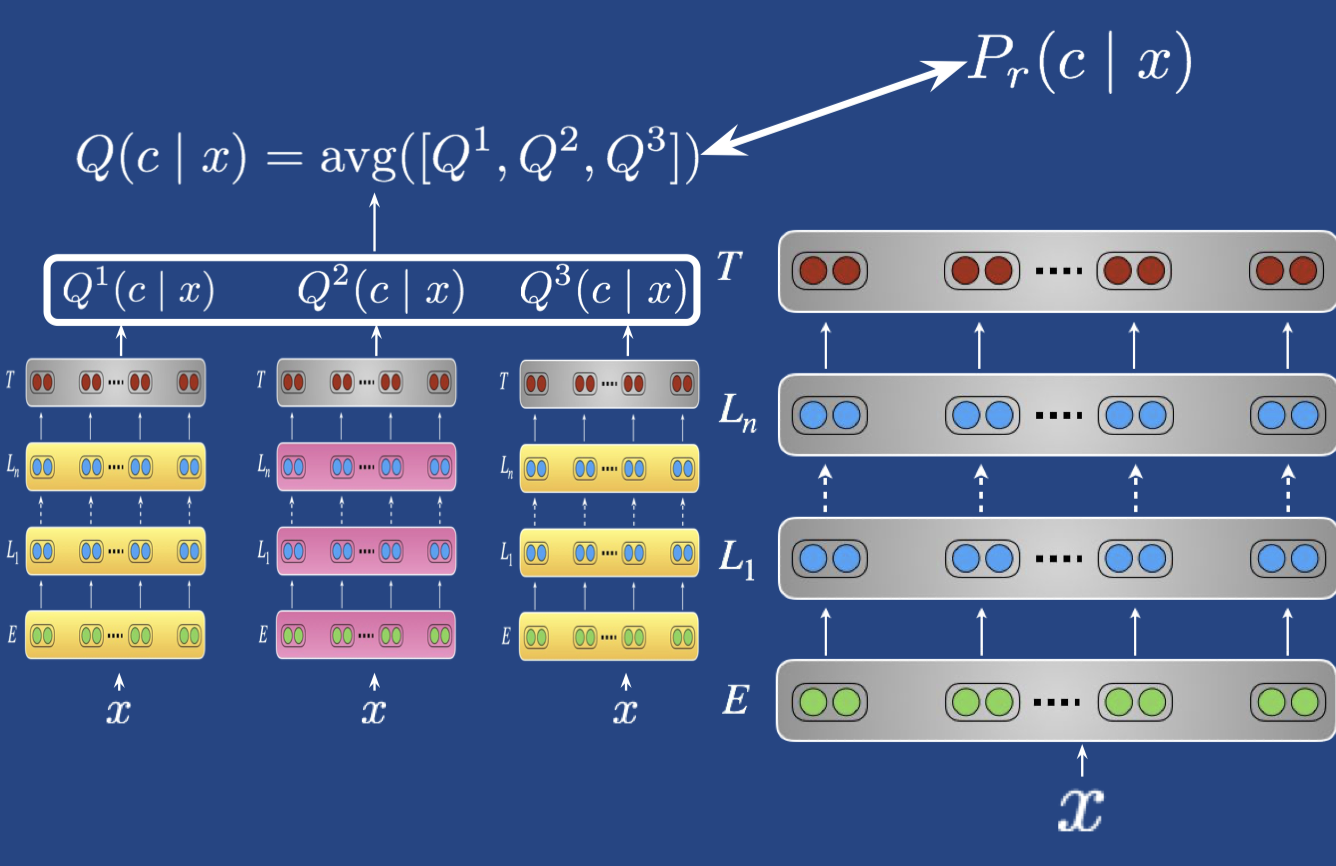
- Knowledge distillation
- 把集成的大模型蒸馏到一个小模型
- 利用 teacher (the ensemble) 模型的 soft targets 来训练一个 student model
- $-\sum_c Q(c|X)log(P_r(c|X))$
- teacher label 的相对概率包含了 teacher 模型怎样泛化的信息
相关资料:
Video: https://vimeo.com/359399507
Slides: https://tinyurl.com/NAACLTransfer
Colab: https://tinyurl.com/NAACLTransferColab
Code: https://tinyurl.com/NAACLTransferCode
Neural Transfer Learning for Natural Language Processing

